When it comes to editing voices, it’s a job filled with variety, constantly reacting to what hits the ears. While an initial setup of EQ templates might be a starting point for some, every voice is unique. Women’s voices tend to have wildly different tones and timbres that vary from person to person, and editing seems to be an area that’s often hit-and-miss across music and the spoken word. The NCBI Library of Medicine states that the male speaking voice averages around 60 – 180Hz, while the female voice generally sits around 160 – 300Hz, with roughly an octave’s difference in pitch. Despite this, there seems to be a wild disparity in how women’s voices are treated in general. Perhaps the most common problem can be summarised as cutting too much in the lower areas, and boosting too much in the higher areas when women’s voices are in the mix.
Spoken word
With the podcast industry booming, it’s interesting to observe the difference in the editing of women’s voices compared to men’s. The lack of De-esser treatment, and the copious boosting of high-end frequencies often lead to distraction with every ‘t’ and ‘s’ sound that occurs. Sibilance and harshness can abound, and pull us away from what women are actually saying.
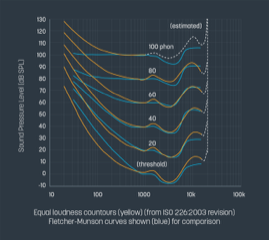
Diagram of the Fletcher-Munson Curve
The Fletcher-Munson Curve measures how our bodies perceive loudness. It is also often referred to as the “equal loudness contour”. Created by Harvey Fletcher and Milden A. Munson in the 1930s, the pair demonstrated how loudness affects the human ear at different frequencies, and where we would perceive (or feel) these pitches and volumes as unpleasant. The most sensitive of these frequency areas that offends the ears lies between 3 – 5kHz, which is the danger zone for sibilance.
Business titan Barbara Corcoran is a fantastic speaker and all-around inspirational career woman. Her voice naturally leans to the high end in pitch and tone and has a propensity for sibilance. When I’d previously watched her on the television show Shark Tank, it was clear that this was her vocal sound, yet when I recently listened to her as a guest on a podcast, I was saddened to hear the edit of Barbara’s voice was jarring in the high-end, and desperately needed a De-esser. I was curious to see how closely my perception of the sound was aligned with what was measurably coming out, so I decided to analyse the podcast in contrast with another recording. I used a Spectral Analysis tool, capturing a snapshot of a word with an ‘s’ sound to compare the two different recordings as fairly as possible, and listened through the same speaker.
Barbara speaking at a TEDx Talk
I first measured Barbara speaking at a TEDx Talk. There was definitely a slight peak in the range of 3-5kHz when measuring Barbara’s talk, however, the peak was only a little above the others, notably its neighbour around 2kHz, and again a little above the 500Hz peak. Audibly, the voice still sounds high and naturally sibilant, however, there is a softness to the ‘s’ sound that does not detract from the talk.
In the bottom graph, the peak is marked around the 3 – 5kHz range and stands alone above the peaks in lower ranges, which demonstrates that this problem area is in fact considerably louder than the other frequencies, and not just perceived to be louder and distracting by the ear.
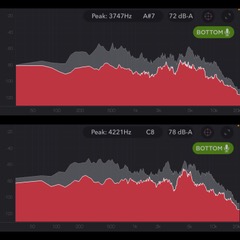
Diagram Barbara Corcoran’s voice in the TEDx Talk (top image) versus as a podcast guest (bottom image).
Music
In music, the same problems surround women singers. Often, in striving to add ‘air’ or ‘brightness’ or ‘clarity’ to a vocal, women’s voices succumb to the harshness in the 3 – 5kHz range. In boosting above 2kHz a little too liberally, and adding reverb or other effects that can further highlight the high-end, women’s voices can end up sounding thin, jarring, and full of squeaky ‘s’ sounds. So how do the experts celebrate the richness and full tonal spectrum of strong women’s vocals, and do it so well?
In a 2011 interview talking about the making of Adele’s album 21, producer Paul Epworth and mix engineer Tom Elmhirst gave a run-down of their process. The pair have worked with some formidable women’s voices, from Florence + The Machine and Amy Winehouse to Adele. On the song Rolling In The Deep, Elmhirst used the Waves Q6 EQ on the chorus vocal, pulling out certain frequencies “very, very heavily”:
“I had the Q6 on the chorus vocal, notching out 930, 1634, and 3175 Hz very, very heavily: -18dB, -18dB, and -12.1dB respectively, with very narrow Q. I also had the EQIII on the lead-vocal sub, notching something out again. Something obviously needed to be taken out. The vocal is the most important thing in the track, and taking those frequencies out allowed me to keep it upfront in the mix, particularly in the chorus. Regarding the outboard, I had the Pultec EQ, Urei 1176, and the Tube-Tech CL1B on the lead vocal sub-insert. The Pultec boosted around 100Hz and 12k. It’s colourful, but not drastic. There was not a lot of gain.”

Diagram of Adele Vocal EQ
When it came to De-essers, Elmhirst likes to add several for precision – on Rolling In The Deep, Elmhirst explained:
“I did use two Waves De-essers, one taking out at 5449Hz and the other at 11004Hz. Rather than use one to try to cover all the sibilance I used two. I do that quite often.”
While on Someone Like You, he went even further, summarising his EQ and De-esser decisions on the piano-vocal track:
“I had three de-essers on the lead vocal in this case, working at 4185, 7413 and 7712 Hz, and I did some notching on the Waves Q10, taking out 537, 2973, and 10899 Hz, with maximum Q in all cases. The Sonnox Oxford EQ simply takes out everything below 100Hz, and it adds a little around 8k.”
Boosting women’s voices
It’s interesting to compare and contrast the rich tapestry of content that is available to us these days, as well as the amount of guidance that is out there. Considering women’s speaking voices sit around 160 – 300 Hz it’s staggering how many guides and training materials generally recommend using a low pass filter cutting up to 200 Hz – where the voice actually is – and boosting from 4 kHz and up – where madness lies. Every voice needs something different, whether softly spoken, cutting through in an arrangement, or leading a band at a show.