
Don’t let the title fool you! Rumori is not rumors, but noises, and that is what this blog is about. All will be revealed as you read on…
Over the last few days, being in isolation as I recover from a bout of Covid, not serious but neither do I want to pass it around, I decided that I needed to re-master my piece that I had hurriedly loaded onto Bandcamp. I decided to make a few changes: extracts of dialogue that seemed ‘out of place or unnecessary, move a few sounds around the stereo image, add a clip that I had forgotten to include, and found a group of three clips that had been coordinated into the second movement but were ‘empty’ by which I mean I had to find and link the .wav files. Also, I had to decide what to do with the bits of dialogue that are central to the piece.
On the 1st of April 2019, I had an operation on my throat which affected my vocal chords. For six weeks after that, I could do no more than squeak and rely on writing messages to communicate. When my voice finally returned, it was raucous and very low in volume; and of course, I could no longer sing. Though I can go into a higher soprano register, the range is limited to just about seven tones from high to low; as a result, it breaks if it tries to go into the lower register so, I don’t sing. My speaking voice is rather like my hair; I never know what it will be like from one day to the next. And since I am no longer with someone, I can go days without speaking, which makes it worse – catch me at about six, early evening, and it’s comfortable. I’d only been in Italy a year at the time of the operation and all the friends I have made since, recognize me with this voice; it’s me, Frà.
The reason I wanted to make this clear is that I overcame my ‘shame’ about my voice and learned to love it. This is important since I use it in several of my pieces. And here is the point of this preamble: Felicia Atkinson, French composer, and sound artist uses her spoken voice but in a rather special way: her dialogues are almost always softly spoken and often submerged into the ambience of the sound so sometimes not heard clearly, while at other times they come through quite clearly. For example, in ‘Pieces of Sylvia’ from her latest album, ‘Image Langage’, the voices are barely discernible, which creates a mood around the piece and maybe encourages one to listen much more closely than might normally be the case. The voices become a dialogue panned hard left and right and gradually become clearer towards the end. You can listen to this track (once) via this Bandcamp link:
https://feliciaatkinson.bandcamp.com/track/pieces-of-sylvia
‘Shirley to Shirley’ on her 2019 album, ‘The Flower and the Vessel’ use a heavily processed dialogue that creates a sense of intimacy between the speaker and the listener but can more easily be heard. Other pieces on this album vary in how the voice is presented but it is always an integral part of the music and always spoken. You can listen to this track (once) via this Bandcamp link:
https://feliciaatkinson.bandcamp.com/track/shirley-to-shirley
So, one of the reasons for the remastering was my unhappiness with the dialogue. I had originally thought to have it ‘submerged’ in the texture of the drones and other accompaniments. However, this piece is quite dense in places, so the voice struggles to come through. I took a decision, therefore, to bring the voice forward and in so doing created a new problem for myself, noise. A problem which I shall clarify and explain how I dealt with it in a while, but first a few considerations.
In last month’s blog, I spoke about being a sound artist due to an absence of typical musical features. In effect, my music (sic.) is noise. As early as 1913, Luigi Russolo, wrote a ‘Futurist’ manifesto L’arte dei Rumori. (The art of Noises). In his manifesto, he posited that the human ear was becoming accustomed to the speed, energy, and noise of industrialization and of urban living. He and his fellow ‘futurists’ even created a ‘noise orchestra’ in their Milan studio and categorized sounds into six families of noise:
- Roars, Thunderings, Explosions, Hissing roars, Bangs, Booms
- Whistling, Hissing, Puffing
- Whispers, Murmurs, Mumbling, Muttering, Gurgling
- Screeching, Creaking, Rustling, Buzzing,[7] Crackling, Scraping [7]
- Noises obtained by beating on metals, wood, skins, stones, pottery, etc.
- Voices of animals and people, Shouts, Screams, Shrieks, Wails, Hoots, Howls, Death rattles, Sobs
Indeed, much of this is also my potential musical palette. The point is that since ‘noise’ is the main material of my Sound art, although I have used traditional musical elements as well, there are no real criteria for any elements of my work, I work at the sounds and how I put them together as would a painter and, on any particular morning, as I review my piece at stages of completion, like the painter, I decide that it is finished as I want it and it conforms to my vision of the work based on my interior narrative.
So, there are three main passages of spoken dialogue. The first is angst-ridden in a context of confusion as much as noise, mainly granular sounds, drones, and harsh metallic sounds. In this context, the sound quality of the vocal clips is less important than the emotional impact of the rawness of some of the dialogue. There are two distinct lines here but abstracted and deliberately misplaced. The suicide extracts from Sylvia Plath’s The Bell Jar were recorded at home so fairly clean apart from a slight bloom in the upper partials of the reverb which sits well in the aggressively noisy ambience of the second movement. My field recorded vocals were mono from my iPhone while walking and remain in mono through the mix but panned left and right by automation in the clips. The only treatment I gave them was the DeNoise – Adobe Audition has a lot of Noise reduction/restoration tools, some of them process based requiring you to capture the sound you want to treat/eliminate before processing, at which point there are many controls allowing one to fine-tune the treatment.
In this particular case, figure 1, I’m looking at the selected mono clip which has some background noise (medium frequency hiss). Now, this is noticeable when the clip finishes and the play head runs onto the empty track; I can hear this clearly as I solo the track. In the context of the second movement, it would not be noticeable but as good practice, I try to work with the best quality clip I can get. Incidentally, although both the SP monologue and the iPhone recording were complete recordings, I cut them up for the reasons I mentioned earlier, and this gives me more flexibility in the composition process.
As you can see from fig 1 below, I am using the DeNoise effect on the clip. I am using the ‘all frequency’ processing focus and, at the top of the gain fader, the tick box allows you to listen to just the noise that is being taken out. This is useful since I can hear if anything is being taken out of the voice itself and I can adjust this with the ‘amount’ fader. If I want to test, check and alter, I can make a time selection and adjust the fader until I get what I want, I can also on /off the effect with the green button at bottom left. If I make an adjustment that might be applicable in other circumstances, I can save it as a pre-set.
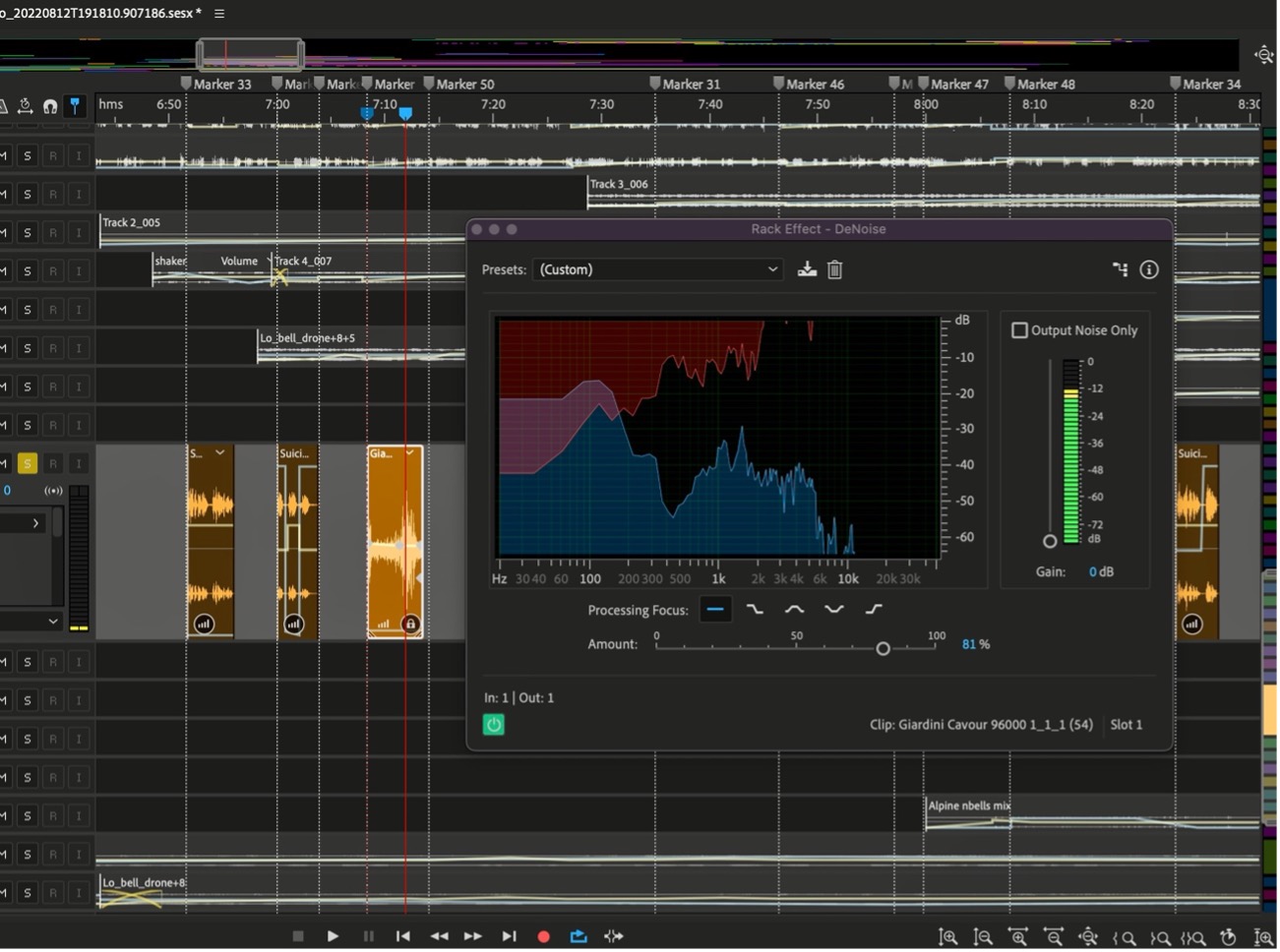
Fig 1

Fig 2
In figure 2, you can see that for this noisy passage I also ‘cut out’ quiet windows to allow the text to be heard more easily (there are more above off-screen) which, to my mind, also creates an interesting effect of being transported elsewhere for the narrative line.
You can listen to this section via this Bandcamp link:
https://frcaston.bandcamp.com/track/the-haunting
The third mood gradually calms down and the texture becomes thinner and quieter and so, it was not necessary to create quiet windows in the texture. However, this is the central movement and is a conversation about the genesis of the piece, both unscripted and personal. That being so, I was not expecting to put it in the foreground so much. However, on repeated listening, I felt it needed to have a bit more presence. So, for each clip, I applied parametric EQ using a pre-set ‘vocal enhancer’ and just tweaking some of the points to reflect the natural spread of frequencies. In figure 3 I have applied the EQ to the clip. I also raised the volume of the clip a couple of dB
And later applied the DeNoise since the EQ introduced some noise. In other words, the aim was to disguise the transition from clip to empty track. This was a problem with working with tape; leader tape is silent and everything else contains noise and the more you do and rerecord, the noise becomes accumulative, which is why we often used Dolby ‘A’ units, even if, for electroacoustic music, they robbed the sound of some of its edge – so there were always decisions to be made.
Getting back to this third mood, the voice is now more forward, and I managed this also by the use of the automation lines in each clip where I could raise or reduce the volume of individual words to improve the feel of the conversation, yet it does not overly draw attention to itself; the purpose was to make this ‘meta-commentary’ sound and feel natural, conversational rather than uniformly even in volume.
You can listen to this via this Bandcamp link:
https://frcaston.bandcamp.com/track/la-conversaci-n
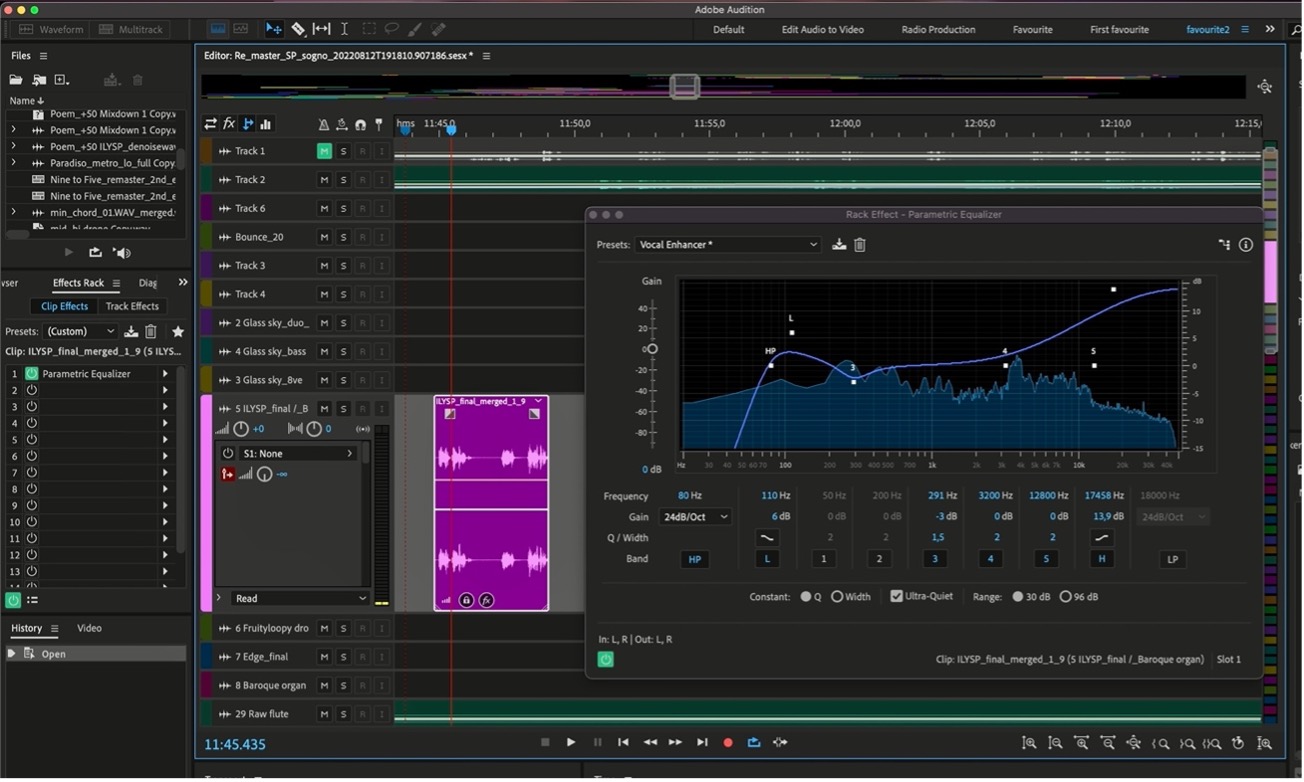
Fig 3
The parametric equaliser is one of my favourite compositional tools since I can really excite upper partials with it; for this, I created my own pre-set ‘snap crackle and pop’ (thank you Kellogs) and was used to make the Swiss alpine cow bells sound like heavy chains in the second mood, at the words, ‘…and she was gassed!’ It also created a spectacular effect from a recording of rain falling on an umbrella which I used in the first mood.
The fourth mood is the quietest and yet it was difficult to balance the reading of the poem with the chamber organ melody beating against the lower drones. Again, I had the problem of noise on the clips which was noticeable as the clip ended and a portion of empty track came under the play head. Again, each clip had parametric EQ applied to give presence to the voice and then DeNoise as with the other clips. Fig 4 shows the treatment of the last voice clip which gives the piece its title: ‘her blacks crackle and drag’. I’m quite happy with my reading of this last line but my voice was too uneven for the close of the poem, so I raised the volume of, ‘her blacks…’ and cut, ‘crackle and drag…’ a little. The clip is panned hard left with a fade at the end.
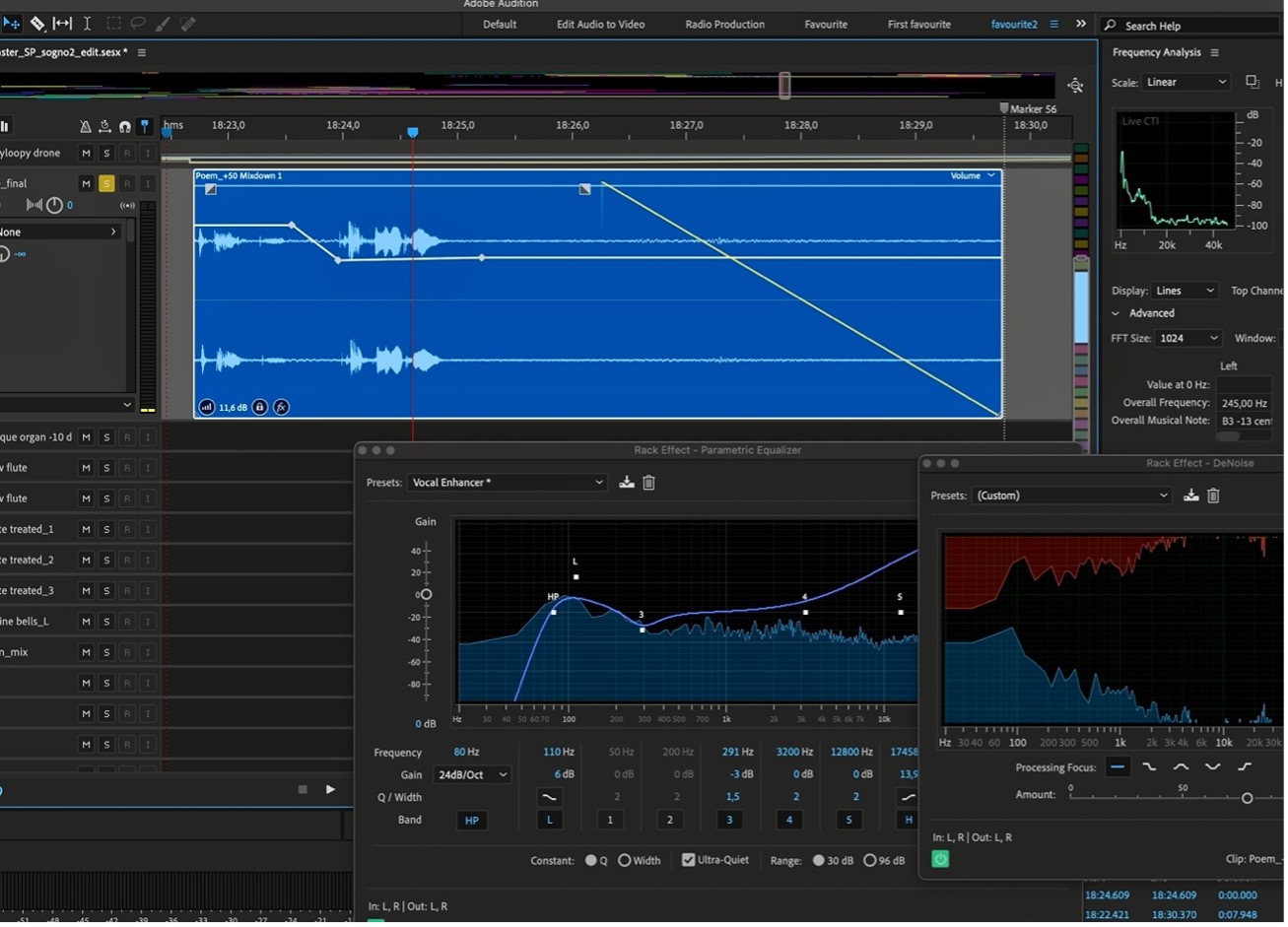
Fig 4
Finally, I’d like to share this link to some tutorials on the Noise reduction/restoration tools in Audition:
https://helpx.adobe.com/audition/using/noise-reduction-restoration-effects.html
If you look at the tutorials and at the individual tools, they claim that noises of various types are removed without affecting the signal; I have found, even with my limited experience of these tools, that the more you use them, the more you understand which routines of which tools serve your purpose.
Most of this work is done in the ‘Waveform editor’ and although I’ve only scratched the surface of these tools (I probably don’t need too many, but their availability gives me another approach to processing my field recordings) and I can already see the potential for processing my clips before taking them into the multitrack editor when I put the composition together; in fact, many of the process treatments can only be done in the ‘waveform editor.
I think I have said this before about Audition, and why I like it so much is that it is a compositional tool as well as improving clips. The spectral frequency display plays a major part in my composition since I use it to select frequency bands to create novel sounds. For example, if I take a full frequency sound with loop potential to become a drone, I can hollow it out by selecting the lowest frequencies, saving that, and then selecting the highest frequencies, sometimes barely audible, and bounce them together to form a drone with no middle frequencies. So then I can play with this and perhaps blend in some movement in middle frequencies from a different source to create a drone that has ‘life’. On the repair side, should you have clicks in the quiet sections, for example, you can quickly use the ‘spot healing brush to paint the clicks out on the spectral frequency display (if you have ever used Photoshop, you’ll find this tool familiar).
Thinking back to Russolo’s classification of noises, I actually work with this material; my approach to the DAW and what it can do are specific to my compositional process. And Audition is still my favorite: I can use MAX MSP with Audition by using the Plugin Soundflower which converts the midi into .wav. But, please, please Adobe, add a Midi input and editor so that I can use some of the other instrumental samples available.
I’ve started learning Mexican Spanish for my planned trip to Mexico at the beginning of March; I’ll probably stay forever, I haven’t decided yet, but I’m aiming to be in Morelia because of the Centro Mexicano para la Música y las Artes Sonoras, Mexico, in Michoacán, which is 4 hours by train from Ciudad de Mexico where I gather, there are Soundgirls. Yay! And I know where I’ll be and with whom on the 8th of March
Hermanas vos quiero a todas