Using psychoacoustics in IEM mixing and the technology that takes it to the next level
SECTION 1
All monitor engineers know that there are many soft skills required in our job – building a trusting relationship with bands and artists is vital for them to feel supported so they can forget about monitoring and concentrate on their job of giving a great performance. But what do you know about how the brain and ears work together to create the auditory response, and how can you make use of it in your mixes?
Hearing is not simply a mechanical phenomenon of sound waves travelling into the ear canal and being converted into electrical impulses by the nerve cells of the inner ear; it’s also a perceptual experience. The ears and brain join forces to translate pressure waves into an informative event that tells us where a sound is coming from, how close it is, whether it’s stationary or moving, how much attention to give to it and whether to be alarmed or relaxed in response. Whilst additional elements of cognitive psychology are also at play – an individual’s personal expectations, prejudices and predispositions, which we cannot compensate for – monitor engineers can certainly make use of psychoacoustics to enhance our mixing chops. Over the space of my next three posts, we’ll look at the different phenomena which are relevant to what we do, and how to make use of them for better monitor mixes.
What A Feeling
Music is unusual in that it activates all areas of the brain. Our motor responses are stimulated when we hear a compelling rhythm and we feel the urge to tap our feet or dance; the emotional reactions of the limbic system are triggered by a melody and we feel our mood shift to one of joy or melancholy; and we’re instantly transported back in time upon hearing the opening bars of a familiar song as the memory centres are activated. Studies have shown that memories can be unlocked in severely brain-damaged people and dementia patients by playing them music they have loved throughout their lives.
The auditory cortex of the brain releases the reward chemical dopamine in response to music – the same potentially addictive chemical which is also released in response to sex, Facebook ‘likes’, chocolate and even cocaine…. making music one of the healthier ways of getting your high. DJs and producers use this release to great effect when creating a build-up to a chorus or the drop in a dance track; in a phenomenon called the anticipatory listening phase, our brains actually get hyped up waiting for that dopamine release when the music ‘resolves’, and it’s manipulating this pattern of tension and release which creates that Friday night feeling in your head.
Missing Fundamentals
Our brains are good at anticipating what’s coming next and filling in the gaps, and a phenomenon known as ‘missing fundamentals’ demonstrates a trick which our brains play on our audio perception. Sounds that are not a pure tone (ie a single frequency sine wave) have harmonics. These harmonics are linear in nature: that is, a sound with a root note of 100 Hz will have harmonics at 200, 300, 400, 500 Hz and so on. However, our ears don’t actually need to receive all of these frequencies in order to correctly perceive the chord structure. If you play those harmonic frequencies, and then remove the root frequency (in this case 100Hz), your brain will fill in the gaps and you’ll still perceive the chord in its entirety – you’ll still hear 100Hz even though it’s no longer there. You experience this every time you speak on the phone with a man – the root note of the average male voice is 150Hz, but most phones cannot reproduce below 300Hz. No matter – your brain fills in the gaps and tells you that you’re hearing exactly what you’d expect to hear. So whilst the tiny drivers of an in-ear mould may not physically be able to reproduce the very low fundamental notes of some bass guitars or kick drums, you’ll still hear them as long as the harmonics are in place.
A biased system
Human hearing is not linear – our ear canals and brains have evolved to give greater bias to the frequencies where speech intelligibility occurs. This is represented in the famous Fletcher-Munson equal-loudness curves, and it’s where the concept of A-weighting for measuring noise levels originated. As you can see from the diagram below, we perceive a 62.5 Hz tone to be equal in loudness to a 1 kHz tone, when the 1k tone is actually 30dB SPL quieter.
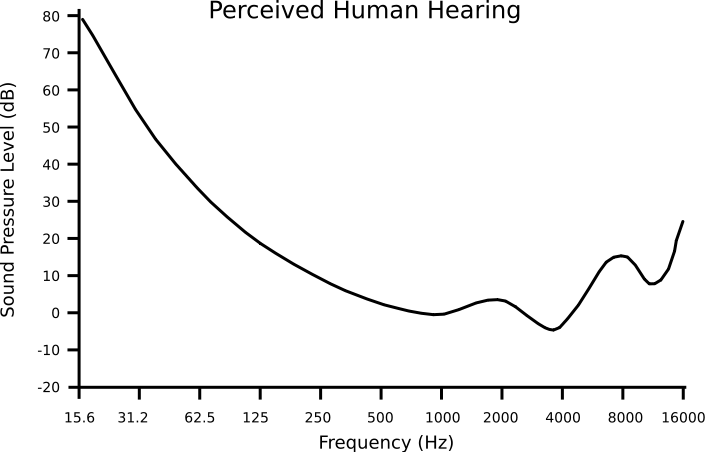
Similarly, the volume threshold at which we first perceive a sound varies according to frequency. The area of the lowest absolute threshold of hearing is between 1 and 5 kHz; that is, we can detect a whisper of human speech at far lower levels than we detect a frequency outside that window. However, if another sound of a similar frequency is also audible at the same time, we may experience the phenomenon known as auditory masking.
This can be illustrated by the experience of talking with a friend on a train station platform, and then having a train speed by. Because the noise of the train encompasses the same frequencies occupied by speech, suddenly we can no longer clearly hear what our friend is saying, and they have to either shout to be heard or wait for the train to pass: the train noise is masking the signal of the speech. The degree to which the masking effect is experienced is dependent on the individual – some people would still be able to make out what their friend was saying if they only slightly raised their voice, whilst others would need them to shout loudly in order to carry on the conversation.
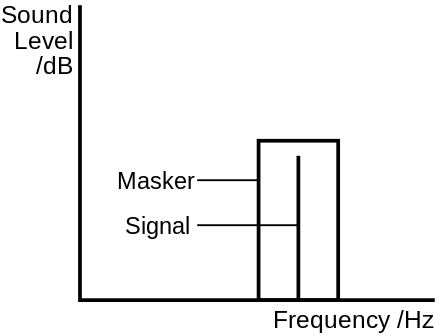
Masking also occurs in a subtler way. When two sounds of different frequencies are played at the same time, as long as they are sufficiently far apart in frequency two separate sounds can be heard. However, if the two sounds are close in frequency they are said to occupy the same critical bandwidth, and the louder of the two sounds will render the quieter one inaudible. For example, if we were to play a 1kHz tone so that we could easily hear it, and then add a second tone of 1.1kHz at a few dB louder, the 1k tone would seem to disappear. When we mute the second tone, we confirm that the original tone is still there and was there all along; it was simply masked. If we then re-add the 1.1k tone so the original tone vanishes again, and slowly sweep the 1.1k tone up the frequency spectrum, we will hear the 1k tone gradually ‘re-appear’: the further away the second tone gets from the original one, the better we will hear them as distinct sounds.
This ability to hear frequencies distinctly is known as frequency resolution, which is a type of filtering that takes place in the basilar membrane of the cochlea. When two sounds are very close in frequency, we cannot distinguish between them and they are heard as a single signal. Someone with hearing loss due to cochlea damage will typically struggle to differentiate between consonants in speech.
This is an important phenomenon to be aware of when mixing. The frequency range to which our hearing is most attuned, 500Hz – 5k, is where many of our musical inputs such as guitars, keyboards, strings, brass and vocals reside; and when we over-populate this prime audio real estate, things can start to get messy. This is where judicious EQ’ing becomes very useful in cleaning up a mix – for example, although a kick drum mic will pick up frequencies in that mid-range region, that’s not where the information for that instrument is. The ‘boom’ and ‘thwack’ which characterise a good kick sound are lower and higher than that envelope, so by creating a deep EQ scoop in that mid-region, we can clear out some much-needed real estate and un-muddy the mix. Incidentally, because of the non-linear frequency response of our hearing, this also tricks the brain into thinking the sound is louder and more powerful than it is. The reverse is also true; rolling off the highs and lows of a signal creates a sense of front-to-back depth and distance.
It’s also worth considering whether all external track inputs are necessary for a monitor mix – frequently pads and effects occupy this territory, and whilst they may add to the overall picture on a large PA, are they helping or hindering when it comes to creating a musical yet informative IEM mix?
Next time: In the second part of this psychoacoustics series we’ll examine the Acoustic Reflex Threshold, the Haas effect, and how our brains and ears work together to determine where a sound is coming from; and we’ll explore what it all means for IEM mixes.